Dans le monde numérique actuel, l'encodage des caractères est un aspect fondamental mais souvent méconnu du fonctionnement des systèmes informatiques. Bien que des formats comme Unicode, et plus particulièrement UTF-8, aient rendu ce processus remarquablement transparent, des incompatibilités peuvent encore survenir, entraînant des affichages erronés de caractères, notamment dans les langues utilisant des accents ou des alphabets spécifiques.
Qu'est-ce que l'encodage ?
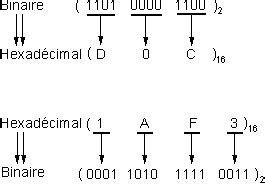
À la base, une chaîne de caractères n'est pas stockée en mémoire sous sa forme lisible, mais plutôt sous forme de séquences binaires de 0 et de 1. La représentation la plus lisible pour nous de ce code binaire est l'hexadécimal. Historiquement, chaque octet pouvait représenter un caractère unique dans des encodages comme l'ASCII ou l'ASCII étendu. Par exemple, le caractère français "é" pouvait être représenté par la valeur hexadécimale "E9" dans l'encodage Windows-1252.
Le défi réside dans la capacité d'un système à déterminer l'encodage correct lors de la restitution du texte. Si l'encodage est mal identifié, des caractères attendus peuvent s'afficher incorrectement. Par exemple, si un texte encodé en UTF-8 est interprété par erreur comme de l'ISO-8859-7 (Grec), certains caractères occidentaux peuvent apparaître fragmentés ou remplacés par des symboles grecs.
L'histoire de l'encodage est marquée par une multitude de codes, chacun répondant à des besoins spécifiques, notamment pour les langues internationales. La gestion de ces différents encodages pouvait devenir complexe dans des environnements multilingues.
Heureusement, Unicode a été créé dans le but d'unifier tous les caractères de tous les encodages existants en une seule table de caractères.
Le format UTF-8 : une solution universelle
Le format Unicode est né de la volonté d'unifier la multitude des codes existants, car un seul octet ne permet de coder que 256 caractères, ce qui était insuffisant pour certains langages nécessitant des alphabets propres ou un grand nombre de symboles.
La solution Unicode consiste à s'affranchir de la contrainte de l'octet unique pour disposer d'une quantité virtuellement infinie de caractères. Les caractères asiatiques, par exemple, peuvent être codés par 4 octets.
Parmi les différentes versions d'Unicode, le format UTF-8 tend à s'imposer en raison de son efficacité en termes de taille mémoire et de sa rétrocompatibilité avec l'ASCII. Dans UTF-8, rien ne distingue un vieux fichier ASCII d'un fichier UTF-8, sauf lors de l'utilisation de caractères spéciaux. Ces caractères spéciaux en UTF-8 sont stockés en hexadécimal sur 2 à 4 octets, en respectant la table de caractères UTF-8. Le principe reste le même : à un "code" correspond un seul caractère dans la table.
Cependant, si une application ne sait pas lire l'UTF-8 ou est forcée à utiliser un encodage différent, chaque octet peut être lu comme un caractère unique. C'est la raison pour laquelle les accents, codés sur deux octets en UTF-8, peuvent s'afficher sur deux caractères au lieu d'un seul lorsque l'encodage est mal déterminé.
Points clés à retenir sur l'UTF-8 :
- Il est rétrocompatible avec l'ASCII.
- Les caractères spéciaux sont stockés sur deux à quatre octets.
- L'application qui "lit" le code hexadécimal doit utiliser le bon encodage.
Les problèmes d'encodage persistants
Malgré la puissance d'UTF-8, des problèmes d'encodage persistent pour plusieurs raisons :
1. L'évolution des systèmes
Les vieux systèmes n'ont pas toujours évolué au même rythme que la révolution Unicode. Des bases de données, applications ou progiciels programmés pour des encodages spécifiques et un octet par caractère peuvent causer des incompatibilités.
2. La spécificité de Microsoft Windows
Microsoft a créé ses propres tables de caractères dérivées des tables ISO-8859-x. Il est difficile de distinguer une table ISO d'une table Windows car elles correspondent à des suites d'octets similaires. De plus, les applications Windows n'utilisent pas toujours l'UTF-8 par défaut, ce qui peut entraîner des confusions lors de l'échange de fichiers entre différents environnements (Windows et Linux, par exemple).
3. Les polices de caractères
L'Unicode permettant de coder un nombre immense de caractères, la création de polices de caractères est devenue une tâche colossale. Les artistes se concentrent souvent sur les langages qui les intéressent, et le standard Unicode peut ajouter de nouveaux caractères, rendant certaines polices obsolètes. Pour les langages exotiques, des polices spécifiques peuvent être nécessaires. Il est important de noter que les polices n'affectent que l'affichage et non le stockage des données.
4. Le BOM (Byte Order Mark)
Le Byte Order Mark (BOM) est une suite d'octets Unicode non imprimables placée au début d'un texte Unicode pour faciliter son interprétation. Bien que non standard ni obligatoire, il aide les applications compatibles à déterminer le format Unicode et l'ordre des octets. Cependant, toutes les applications ne savent pas gérer le BOM. Pour les applications non compatibles, cette suite d'octets est interprétée comme des caractères normaux, menant à l'affichage de symboles étranges comme "" (correspondant à la chaîne hexadécimale EF BB BF en UTF-8).
Le BOM peut également prêter à confusion car il est invisible et optionnel dans un fichier UTF-8, rendant difficile la distinction entre un fichier avec BOM et un fichier sans. Il existe également plusieurs types de BOM pour différents formats Unicode, souvent moins compatibles.

Déterminer l'encodage d'un fichier texte
Il est souvent utile de vérifier le format d'un fichier, qu'il soit généré automatiquement, reçu d'un fournisseur ou créé manuellement. Des éditeurs hexadécimaux standard peuvent aider à cette vérification.
Sur Windows : Lancez PowerShell et utilisez la commande fhx nom_du_fichier.txt.
Sur Linux : Utilisez la commande file -bi nom_du_fichier.txt pour une première indication, puis xxd nom_du_fichier.txt pour visualiser le contenu hexadécimal et le BOM.
La présence d'un tag BOM au début du fichier indique un format Unicode spécifique :
- UTF-8 : EF BB BF
- UTF-16 Big Endian : FE FF
- UTF-16 Little Endian : FF FE
- UTF-32 Big Endian : 00 00 FE FF
- UTF-32 Little Endian : FF FE 00 00
Il est crucial de se souvenir que l'absence de BOM ne signifie pas que le fichier n'est pas Unicode. Au contraire, il peut être nécessaire de le supprimer pour améliorer la compatibilité avec certaines applications.
Exercice avancé en VBA : Gérer le BOM
Lors de la création de fichiers Unicode avec VBA pour des applications sensibles au format, des difficultés peuvent survenir concernant le BOM. Les limitations de VBA incluent :
- La commande Print #1 ne permet pas d'enregistrer en UTF-8, entraînant la perte des caractères Unicode.
- La méthode SaveToFile des objets "ADODB.Stream" crée systématiquement un BOM EF BB BF pour les fichiers UTF-8, sans option pour le désactiver.
Pour contourner ces limitations, il est possible d'utiliser un flux binaire pour écrire des fichiers UTF-8 sans BOM.
Exemple de code VBA pour créer des fichiers UTF-8 avec et sans BOM :
Sub Créer_UTF8()Dim lStreamUTF8BOM, lStreamBinaireSansBOM As ObjectSet lStreamUTF8BOM = CreateObject("ADODB.Stream")Set lStreamBinaireSansBOM = CreateObject("ADODB.Stream")' Configuration du flux pour UTF-8 avec BOMlStreamUTF8BOM.Type = 2 ' Type TextelStreamUTF8BOM.Mode = 3 ' Mode Lecture et EcriturelStreamUTF8BOM.Charset = "UTF-8"lStreamUTF8BOM.OpenlStreamUTF8BOM.WriteText "Ligne 1 : un caractère très spécial Unicode : Ж = D0 96" & vbCrLflStreamUTF8BOM.WriteText "Ligne 2" & vbCrLf' Sauvegarde du fichier avec BOMlStreamUTF8BOM.SaveToFile "c:\Temp\UTF8avecBOM.txt", 2 ' 2 = écraser' Configuration du flux binaire pour écrire sans BOMlStreamBinaireSansBOM.Type = 1 ' BinairelStreamBinaireSansBOM.Mode = 3 ' Mode Lecture et EcriturelStreamBinaireSansBOM.Open' Copie du contenu du flux UTF-8 en sautant les 3 premiers octets (le BOM)lStreamUTF8BOM.Position = 3lStreamUTF8BOM.CopyTo lStreamBinaireSansBOM' Sauvegarde du fichier sans BOMlStreamBinaireSansBOM.SaveToFile "c:\Temp\UTF8sansBOM.txt", 2 ' 2 = écraserlStreamBinaireSansBOM.FlushlStreamBinaireSansBOM.CloselStreamUTF8BOM.FlushlStreamUTF8BOM.CloseEnd SubAprès exécution de ce code, vous pouvez vérifier les fichiers générés dans C:\TEMP\ à l'aide des commandes PowerShell mentionnées précédemment.
Les caractères invisibles et leur utilisation
Le concept de "caractère invisible" ou "texte caché" désigne des caractères qui ne sont pas directement visibles à l'écran mais qui occupent un espace ou remplissent une fonction spécifique. Il peut s'agir de caractères Unicode vides (comme U+0020, U+00A0, U+FEFF) ou de marques de formatage qui indiquent la présence d'éléments de mise en page sans être imprimables.
Utilisations courantes des caractères invisibles :
- Espaces sans rupture : Pour s'assurer que deux mots (par exemple, un prix et sa devise) restent sur la même ligne.
- Masquage de texte : Écrire du texte en blanc sur fond blanc ("police blanche") pour le rendre invisible, souvent utilisé pour le SEO (répétition de mots-clés) sur les sites web, bien que cette pratique soit déconseillée.
- Personnalisation de noms d'utilisateur : Dans les jeux vidéo ou les messageries, pour différencier des noms identiques ou utiliser des caractères spéciaux non affichés.
- Formatage de documents : Les marques de formatage aident à structurer un document sans être imprimées.
Il est possible de masquer du texte ou des images dans des documents, par exemple dans MS Word, pour des impressions sélectives ou pour laisser des notes personnelles.

Les noms de domaine internationalisés (IDN)
Initialement, les noms de domaine étaient limités à l'alphabet latin sans caractères accentués. Les noms de domaine internationalisés (IDN) ont été introduits pour surmonter ces obstacles linguistiques. Ils utilisent un mécanisme de conversion appelé Punycode pour transformer les caractères spéciaux en une série de lettres et de chiffres reconnus par le système DNS, tout en restant lisibles dans la langue d'origine.
Par exemple, le nom de domaine français "réussir-en.fr", contenant un caractère accentué, est converti en "xn--russir-en-b4a.fr". Les caractères accentués couramment utilisés en français (é, à, ç, ë, etc.) peuvent être intégrés dans les noms de domaine.
Complications techniques et solutions :
L'utilisation de caractères accentués dans les noms de domaine peut entraîner des complications avec des logiciels anciens ou non mis à jour, qui peuvent mal interpréter ces caractères, conduisant à des erreurs ou à des chaînes de caractères corrompues ("mojibake").
Face à ces problèmes, une stratégie recommandée est d'enregistrer les deux variantes du nom de domaine : une avec les caractères accentués et une autre sans. Cela garantit l'accessibilité et évite que les utilisateurs ne "corrigent" le nom en supprimant les accents par méconnaissance.

Les IDN peuvent influencer positivement le SEO en améliorant la pertinence et la visibilité d'un site web dans des contextes linguistiques spécifiques. Les moteurs de recherche et les applications internet prennent bien en compte les IDN. Il est important de choisir une extension qui supporte les IDN et de se renseigner sur les règles spécifiques auprès du registre concerné (par exemple, l'Afnic pour le .fr).
Adopter une stratégie de portefeuille de noms de domaine, incluant les variantes avec et sans caractères accentués, est une mesure de protection du trafic et de la marque en ligne. Des redirections doivent ensuite être mises en place vers le nom de domaine principal pour une expérience utilisateur optimale.